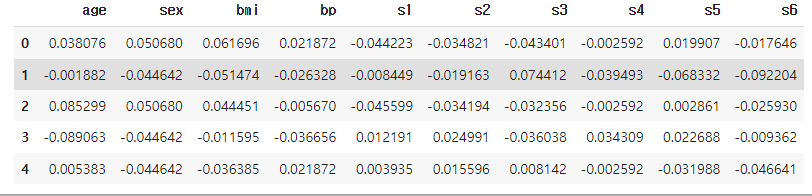
#Linear line의 생성
line_x = np.linspace(np.min(X_test['s6']), max(X_test['s6']), 10)
line_y = sim_lr.predict(line_x.reshape(-1,1))
print(line_x)
print(line_y)
#Test data를 표현
plt.scatter(X_test['s6'], y_test, s=10, c='black')
plt.plot(line_x, line_y, c='red')
plt.legend(['Test data sample','Regression line'])이번 예제에서는 혈당을 나타내는 feature인 's6' 하나를 가지고 당뇨 예측을 해본다.
알고리듬 임포트
from sklearn.linear_model import LinearRegression
sim_lr = LinearRegression()
데이터 쪼개기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
data, label, test_size = 0.2, random_state=2023)
혈당 수치만 가져와서 sklearn에 맞는 array형태로 바꾸기
X_train['s6'].values.reshape((-1,1)), y_train
학습
sim_lr.fit(X_train['s6'].values.reshape((-1,1)), y_train)예측
y_pred = sim_lr.predict(X_test['s6'].values.reshape((-1,1)))
from sklearn.metrics import r2_score
print('단순 선형 회귀, R2: {:.2f}'.format(r2_score(y_test, y_pred)))
print('단순 선형 회귀 계수(w) : {:.2f}, 절편(b): {:.2f}'.format(sim_lr.coef_[0],sim_lr.intercept_))
출력>
단순 선형 회귀, R2: 0.16
단순 선형 회귀 계수(w) : 586.70, 절편(b): 152.60
시각화
#Linear line의 생성
line_x = np.linspace(np.min(X_test['s6']), max(X_test['s6']), 10)
line_y = sim_lr.predict(line_x.reshape(-1,1))
print(line_x)
print(line_y)
#Test data를 표현
plt.scatter(X_test['s6'], y_test, s=10, c='black')
plt.plot(line_x, line_y, c='red')
plt.legend(['Test data sample','Regression line'])
점과 선의 괴리감이 커서 좋은 모델은 아닌 걸 알 수 있다 : 예측율이 떨어질 듯
'machine_learning' 카테고리의 다른 글
| 비지도 학습 Clustering(1) - 예제용 와인 데이터 전처리 (0) | 2023.05.01 |
|---|---|
| sklearn_regression 3. Machine Learning Algorithm Based Regression (0) | 2023.04.28 |
| sklearn_regression 1. 예시용 당뇨병 데이터 정리 (0) | 2023.04.28 |
| sklearn_classification 평가 방법 (0) | 2023.04.28 |
| sklearn_classification 4. Decision Tree(의사결정 나무), Random Forest (0) | 2023.04.28 |