당뇨병 데이터로 best model 뽑은 이후 과정 : 실험에 사용했던 데이터를 저장(Data store)&관리하고 서비스 배포
import numpy as np
from azureml.core import Dataset # 데이터 관리해주는 모듈
#실험에 사용했던 데이터 넘파이로 저장
np.savetxt('feature.csv', X_train, delimiter=',') # X_train의 내용을 features.csv라는 이름으로 저장, 구별자는 ','
np.savetxt('labels.csv', y_train, delimiter=',')
파일 두개 생성 완료
# 데이터 스토어에 업로드하는 작업
datastore = ws.get_default_datastore # 데이터 스토어 변수로 저장
datastore.upload_files(files=['./feature.csv','./labels.csv'], # 업로드할 (파일 현재/)경로파일 이름
target_path = 'diabetes-experiment/', # 경로 지정
overwrite=True #이전 파일이 있을 경우 덮어쓰기
)
이제 data > datastore> workspace 선택 > 아까만든 당뇨병 실험 폴 더 안에 두개의 파일 올라가 있을 것이다.
# 저장된 정보 가져오기
feature_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore,'diabetes-experiment/features.csv')])
label_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore,'diabetes-experiment/labels.csv')])
# best model 등록하는데 필요한 패키지
import sklearn
from azureml.core import model Model
from azureml.core.resource_configuration import ResourceConfiguration
# 시스템에 모델의 등록
model = Model.register(workspace=ws,
model_name = 'diabetes-experiment-model', # 모델 이름
model_path = f'./{str(best_run.get_file_names()[0])}', # 모델의 경로, f붙임으로써 format형태로 지정
model_framework=Model.Framework.SCIKITLEARN, # 학습에 사용한 프레임워크 저장
model_framework_version=sklearn.__version__, # 프레임워크 버전
sample_input_dataset = feature_dataset,
sample_output_dataset=label_dataset,
resource_configuration=ResourceConfiguration(cpu=1, memory_in_gb=0.5), # 해당 모델을 돌리는데 필요한 cpu와 메모리
description='Ridge regression model to predict diabetes progression', # 설명
tags= {'area':'diabetes', 'type':'regression'}
)
모델이 등록된 걸 볼 수 있다.
배포하고 나면 endpoint도 생길 것이다
# 모델 잘 등록이 되었는지 확인
print('Model name: ', model.name)
print('Model Version:', model.version)
출력>
Model name: diabetes-experiment-model
Model Version: 1
이제 모델을 실제로 배포해보자
# 모델의 배포
service_name = 'diabetes-service'
service = Model.deploy(ws, service_name, [model], overwrite=True) # 워크스페이스 지정, 서비스 이름지정, 모델지정-여러개를 한꺼번에 배포할 수 있어서 리스트 타입으로 지정, 덮어쓰기 지정
service.wait_for_deployment(show_output=True) # 배포하는 중간 아웃풋 보여주기
배포된 모습
1. endpoint
2. 테스트 가능
# Notebook에서도 아래와 같이 예측 테스트 해볼 수 있다
import json
input_payload = json.dumps({
'data': X_train[0:2].values.tolist(),
'method': 'predict'
})
output = service.run(input_payload)
print(output)
데이터를 가지고 오면 raw data가 되고 여기서 우리가 필요한 형태로 데이터 전처리 과정을 거쳐야한다.
그때 필요한 메타데이터를 따로 관리하기도 하고 그래서 전처리를 해서 나온것이 features(feature engineering)
그리고 이 feature를 가지고 트레이닝과 테스트셋으로 나눠서 트레이닝셋에 알고리즘을 먹이고 파라메타를 조정한다. 여기서 데이터를 학습해서 넣은 것이 모델이다.
그리고 이 모델에 테스트셋을 넣어 평가해보고 괜찮으면 저장하고 배포한 것이 API
1. Automates ML > Create a new Automated ML job 눌러서 시작
2. 데이터를 먼저 만들어주자
create 눌러 시작
이미 예제 파일이 로컬에 있음으로 from local file을 체크하고 넘어간다
저장 공간을 지정
업로드할 파일 선택
데이터의 구조 보기
file format : delimited 구분자로 구별되어있다
ㄴ보면서 빼줘야할 column을 미리 생각해보자
-첫번째 열
-name
-티켓번호
schema(구조)에서는 아까 빼버린 옵션을 꺼버리면 된다
그리고 결과적으로 예측을 할 survived가 0, 1의 정수형으로 되어있는데 컴퓨터는 이 값이 그냥 숫자로 착각할 수도 있기 때문에 삶과 죽음 값 2개 밖에 없음을 나타내기 위해 bool타입으로 바꿔준다
전체적인 overview에서 create까지 눌러주면 DataSet이 만들어진 것(안보이면 refresh)
3.
만들어진 데이터 셋 누르고 next 눌러 새로운 job을 만든다
이름 짓고/ 라벨 데이터 정하고 / 이걸 돌린 컴퓨터 설정(지난 과정에서 만든 vm)
4. 어떤 문제를 풀것인지 체크 (타이타닉 예제는 산자/죽은 자를 나누는 classification 문제)
deep learning을 누르면 dl까지 해주고 아니면 sklearn만 사용. 이번엔 체크해보자
next 하기전 view additional configuration settings에서 Primary metric(지표) 정해주고
Blocked model에서 아예 시도도 안해도 될 것같은 알고리듬을 정해준다.
exit criterion은 시간이 얼마나 걸렸을 때 그만 중단시킬지 정해주는 것
max concurrent iteration은 몇개를 동시에 돌릴지 정한다(올릴 수록 돈도 많이 듦^^)
그 후 저장하고 next
4. validate and test, 모델 평가방법
validatio type: (1)train-validation split 은 학습/테스트용으로 쪼개서 해서 테스트 (2)user validation data 테스트용 데이터 따로 줘서 사용
finish를 눌러준다
completed되기 전 만들어지는 과정에서도 models 들어가면 만들어지며 list up되는 과정 볼 수 있다
알고리즘 중 같은 정확도라면 duration이 짧은 게 좋다(여기선 standardScalerWrapper로 전처리, XGBoostClassifier가 알고리듬)
눌러서 들어가보면 그 모델에 대한 설명 볼 수 있다, /view generated code 하면 코드도 활용 가능./Metric을 보면 해당 알고리즘의 지표들을 보여준다./Data transformation에서는 데이터 전처리 과정을 볼 수 있다.
세번째 방법 : Notebooks
이번에는 당뇨병 데이터를 예제로 사용
파일을 새로 만들어준다
python 버전 바꾸기
애저 쪽 기능을 다 쓰려면 인증을 눌러줘야한다!
# Azure Machine Learning은 Microsoft에서
# Workspace는 머신 러닝 프로젝트의 모든 구성 요소를 포함하는 최상위 개체
# 애저 쪽 기능 임포트
from azureml.core import Workspace
# 워크스페이스 쪽 현재상황 보는 참조 변수 만들기
ws = Workspace.from_config()
# 워크스페이스의 이름 및 다른 몇가지 정보 더보기
print('Workspace name:' + ws.name,
'Azure region:' + ws.location,
'Subscription ID:' + ws.subscription_id,
'Resurce group:' + ws.resource_group
)
실험 공간? 워크 스페이스 내에 또 연구실이 있고 이 안에서 파이썬을 돌리도록 되어있다.
# 실험 공간을 준비
from azureml.core import Experiment
# 실험을 할 땐 워크스페이스에 만들어주고 실험의 이름도 지정
experiment = Experiment(workspace=ws, name='diabetes-experiment')
# 데이터 준비
from azureml.opendatasets import Diabetes
# 데이터 쪼개는 데 쓰는 모듈 임포트
from sklearn.model_selection import train_test_split
#pandas 데이터 프레임 형태로 보기, 이미 보관된 데이터를 가져오는 거라 get_tabular를 이용,dropna()로 빠진 행 지우기
x_df = Diabetes.get_tabular_dataset().to_pandas_dataframe().dropna()
# Y값만 꺼내서 저장
y_df = x_df.pop('Y')
# 데이터 쪼개기
X_train, X_test, y_train, y_test = train_test_split(x_df, y_df, test_size=0.2, random_state=66)
# 쪼개진거 확인
print(X_train)
pandas 데이터 프레임 형태로 보기 단계의 표. Y(당뇨)가 라벨이 될것이고 나머진 Feature이 될 것이다
# 모델 훈련, 로그, 모델 파일 관리
# 알고리듬/ 평가지표/ 저장 모듈 부르기
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
# 수학적 도구 임포트
import math
# 학습을 시키기 위한 alpha 값 만들기(성능 비교위해)
alphas = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
# 테스트
#for alpha in alphas:
#
# model = Ridge(alpha=alpha)
# model.fit(X_train, y_train) # 데이터 학습
# y_pred = model.predict(X_test) # 예측 결과 저장
# mse = mean_squared_error(y_test, y_pred) # 오류 저장
#
# print('model_alpha={0}, mse={1}'.format(alpha, mse)) # 결과 보기
오류 측정을 rmse로 바꿔서 해주기 (mse에 루트준 값), 실험 로그 남기기
# 테스트
for alpha in alphas:
#실험의 기록
run = experiment.start_logging() # 실험 시작, 로그 시작
run.log('alpha_value',alpha) # 로그 기록 항목1
model = Ridge(alpha=alpha) # Ridge 회귀 분석 모델을 만들고,Ridge(alpha=alpha) 부분은 alpha 매개 변수를 사용하여 규제 강도를 지정
model.fit(X_train, y_train) # 데이터 학습
y_pred = model.predict(X_test) # 예측 결과 저장
rmse = math.sqrt(mean_squared_error(y_test, y_pred)) # 오류 저장
run.log('rmse', rmse) # 로그 기록 항목2
print('model_alpha={0}, rmse={1}'.format(alpha, rmse)) # 결과 보기
# 모델을 파일로 저장하는 부분
model_name = 'model_alpha_' + str(alpha) + '.pkl' # 파일 이름 정하기
filename = 'outputs/' + model_name # 경로 + 모델명
#joblib은 파이썬의 객체 직렬화 라이브러리로서, 메모리에 상주하는 파이썬 객체를 파일 형태로 저장하거나 읽어들이는 기능을 제공
joblib.dump(value=model, filename = filename) # 저장명령으로 임시저장(dump), 내용은 모델,저장할 파일의 이름
# Azure ML Service 에 모델 파일을 업로드 하는 부분
run.upload_file(name=model_name, path_or_stream=filename)
run.complete() # 기록끝
print(f'{alpha} experiment completed')
실험 완료
실험이 끝났으면 파일 창 refresh하면 훈련시킨 모델들이 저장된 걸 볼 수 있다
job 에셋 > 당뇨병 실험 들어가기
각각의 실험에 대한 모델들을 볼 수 있다.(Azure ML Service 에 모델 파일을 업로드 하는 부분)
각각의 모델에 들어가면 설정했던 alpha_value과 오류값 측정등을 볼 수 있다.
다시 해당 노트북에서 expriment 치면 리포트 등 볼 수 있다.
expriment
모델 중 가장 best 모델 탐색 후 다운로드(rmse가 가장 낮은 모델)
# Best Model을 탐색 후 다운로드
minimum_rmse = None # 오류도
minimum_rmse_runid = None # 몇번 째 실험인지 인덱스
for exp in experiment.get_runs(): # 실험 돌리기
run_metrics = exp.get_metrics(); # 평가지표 돌리기
run_details = exp.get_details(); # 실험 디테일 돌리기(몇번째 실험인지 알기위해 사용하는 듯)
run_rmse = run_metrics['rmse'] # 평가지표중에 rmse 돌리기
run_id = run_details['runId'] # 디테일 중 몇번째 실험인지 돌리기
# 가장 낮은 RMSE 값을 가진 실행 ID를 구하는 부분
if minimum_rmse is None: # minimum_rmse가 none일 때
minimum_rmse = run_rmse # 평가지표 돌리고
minimum_rmse_runid = run_id # minimum_rmse id 도 돌려
else:
if run_rmse < minimum_rmse: # rmse가 기존 minimum rmse보다 작으면
minimum_rmse = run_rmse # 걔가 새로운 minimum으로 대체
minimum_rmse_runid = run_id # id도 같은 이치로 작업
print('Best run_id: ' + minimum_rmse_runid)
print('Best run_id rmse: ' + str(minimum_rmse))
# best 파일 이름 확인
from azureml.core import Run
best_run = Run(experiment=experiment, run_id=minimum_rmse_runid)
print(best_run.get_file_names())
#베스트 모델 파일 다운로드
best_run.download_file(name=str(best_run.get_file_names()[0]))
#이제 파일 목록에 베스트 버전 모델이 다운로드 되어있다.
과정에 오류가 생기면 Jobs에 해당 실험들어가 뭔가 값이 빠지거나 여전히 생성중인 파일이 있는 것인지 확인하고 삭제 재실행한다
git clone https://github.com/Azure-Samples/azure-voting-app-redis.git
# 파일 확인
ls
# clone한 프로젝트로 들어가기
cd azure-voting-app-redis
# 폴더 구조보기
ls -al
clone한 파일 안 구조
(4) yaml파일 살펴보고 docker compose 기능 알아보기
# yaml 파일 내용보기
cat docker-compose.yaml
---------------------내용---------------------------
version: '3'
services:
azure-vote-back:
image: mcr.microsoft.com/oss/bitnami/redis:6.0.8
container_name: azure-vote-back
environment:
ALLOW_EMPTY_PASSWORD: "yes"
ports:
- "6379:6379"
azure-vote-front:
build: ./azure-vote
image: mcr.microsoft.com/azuredocs/azure-vote-front:v1
container_name: azure-vote-front
environment:
REDIS: azure-vote-back
ports:
- "8080:80"
---------------------------------------------------------
#위의 내용으로 보아 docker-compose.yaml파일은 azure-vote-back(백엔드) 과 azure-vote-front(프론트엔드) 컨테이너로 이루어져 있다
# 고로 compose는 필요한 컨테이너를 한꺼번에 돌리게 사용하게끔 하는 것이다.
(5) docker compose 설치
sudo apt-get install docker-compose #docker-compse 도구 설치
(6) docker compose 실행
docker-compose up -d # docker compose 파일을 찾아서 실행시킨다, yaml파일 속 컨테이너의 image를 만들고 daemon모드로 실행한다,
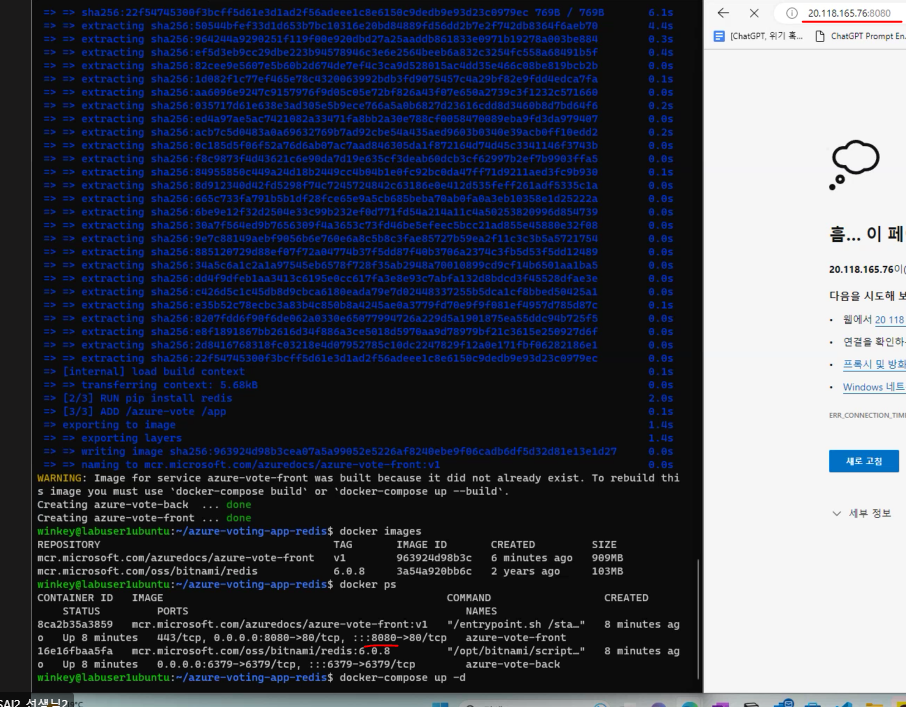
docker images # 두개의 이미지 잘 설치됐나 확인
docker ps # 실행 중인 컨테이너 확인, 주소들이 할당된 것도 볼 수 있다.
(7) 컨테이너들이 잘 실행되는지 확인-접속을 ip address로 접속해보자
-가상머신의 ip주소 확인
-'ip주소:cmd창의 프론트엔드 포트' 넘버 넣어서 접속해보기 : 안됨
그 이유: 일단 가상머신은 네트워크가 방화벽에 쌓여있고 열어서 사용하는 방식을 사용하기 때문
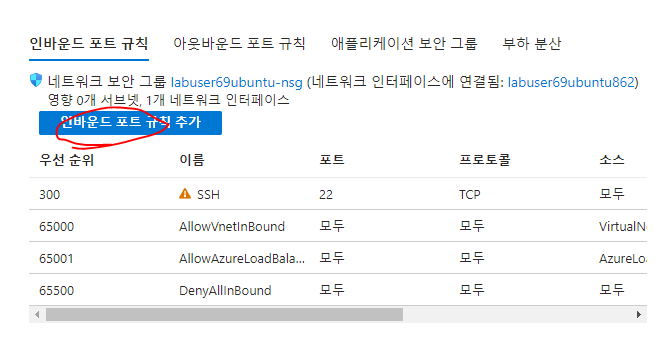
네트워크 8080에 대한 방화벽 풀기 위해 애저 포탈 가상머신의 네트워킹 설정 > 인바운드(서버쪽으로 들어오는 트래픽
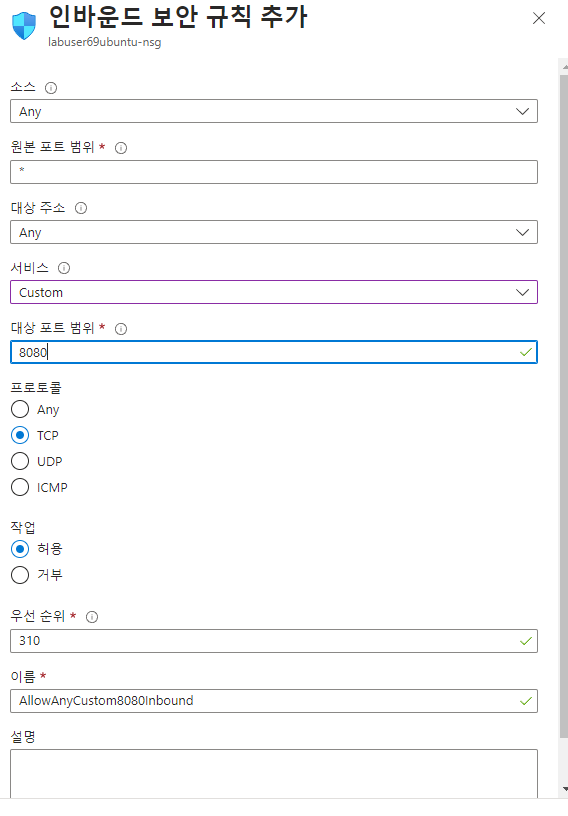
)/아웃바운드 포트 규칙이 있다. 또 클라우드는 인바운드 트래픽에 대해서는 전혀 비용을 받지 않는다는 것도 다시 상기해보며 인바운드 포트 규칙 추가 해보기
우리는 지금 웹에 접속하는 것이기 때문에 http를 해도좋지만 우리가 원하는 포트 선택을 위해 custom하고 8080입력.
만들고 나면 이제 규칙이 추가돼고 방화벽에 규칙이 적용될 것이다.
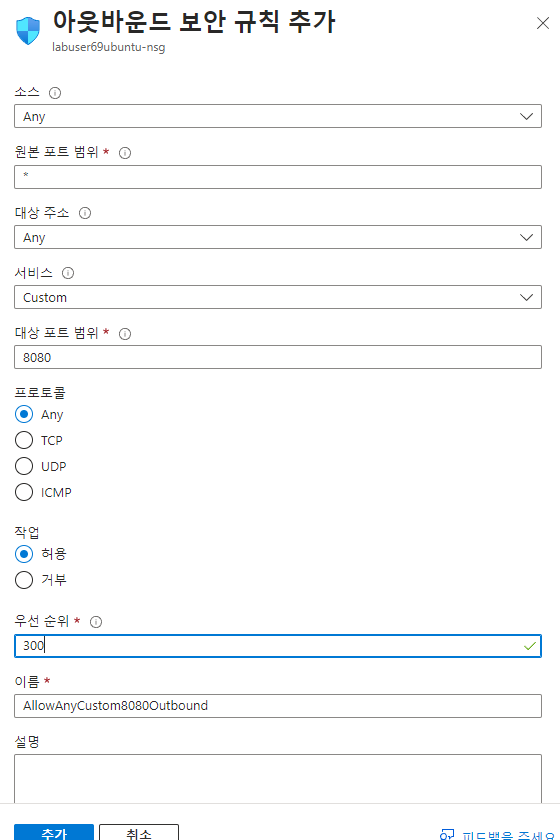
이제 아웃바운드 규칙도 만들어준다.
이제 다시 시도해보면 접속이 된다.
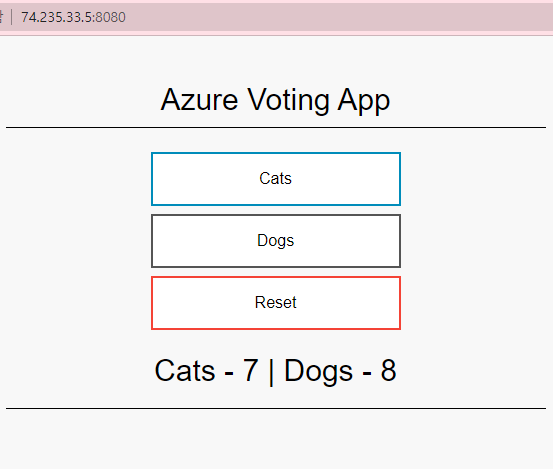
실행되는 앱
컴포즈 파일에 있던 것 중지시킨다
# 메모리 자체에서 compose를 제거(서비스 자체를 없앰)
docker-compose down
# 확인
docker ps
docker images # image파일만 남아있다.
# 서비스 다시 살리기
docker-compose up
<(자습서2)컨테이너 레지스트리(ACR) 만들기>
위에 과정은 docker 이미지를 만들고 compose 파일로 만들어보는 것 까지였다.
그런데 다른데 배포할 때는 이미지를 어딘가 저장해야할 것이다(docker hub 등)
지난 시간에는DockerHub를 이용해 이미지를 저장하고 minikube를 이용하여 워크노드와 pod등을 관리했다.
이번 과정에서는 클라우드를 이용해 ACR(Azure container resistry) 도커 이미지를 Push해서 넣어보자
또 클라우드 쿠버네티스(AKS)를 통해 pod를 만들고 ACR에서 이미지를 가져오고 관리하게 해보자: 실제 서비스
(1)Azure cli를 설치하고 로그인- ubuntu ver, 설치옵션에서 cmd에서 할 것(옵션1만 해도 된다)
# 설치확인
az --version
#az 명령어?
#azure와 관련된 명령 내릴 수 있는 명령어
az login
# 아래 나온 주소+코드로 접속
Azure CLI 명령어 도구 만들기(Azure Container Registry 만들기)
# Azure CLI에서 리소스 그룹의 목록을 보기
az group list
# 테이블 형태로 그룹 리스트를 보여주는데 | 0503 키워드들어간걸로 찾아줌 (여기서 0503은 내 리소스그룹이름)
# '|'(pipe line)는 한 명령의 출력을 다른 명령에 이어줘서 사용한다.
# grep은 키워드로 찾기
az group list --output table | grep 0503
# 결과를 txt 파일로 만들어 저장해버리기 (> 파이프를 꺽쇠모양으로)
az group list --output table > a.txt
#파일 지우기
rm a.txt
# az acr 만들기, sku는 스펙을 뜻한다
az acr create --resource-group 0503 --name 0503acr --sku Basic
# (az acr create --resource-group myResourceGroup --name <acrName> --sku Basic)
# 결과보기
디렉토리에서는 서버들이 하나로 연결돼어 있다. 그래서 어느 서버에 들어가던 디렉토리에 인증을 받고 들어가서 하면 다 통일된 관리 가능
마이크로소프트에서는 active directory(ad)라는 것을 만듦, 그 후 클라우드 서비스가 나오며 개념이 확장되어 Azure active directory(aad)가 나오게 된다.
# image 목록 확인
docker images
#ACR에서 azure-vote-front 컨테이너 이미지를 사용하려면 레지스트리의 로그인 서버 주소로 이미지에 태그를 지정해야 함. 태그는 이미지 레지스트리에 컨테이너 이미지를 푸시할 때 라우팅에 사용
az acr list --resource-group 0503 --query "[].{acrLoginServer:loginServer}" --output table
# 출력에 acr 주소가 생성
# acr 주소 사용하여 image들이 acr을 바라보도록 tagging
docker tag mcr.microsoft.com/azuredocs/azure-vote-front:v1 0503acr.azurecr.io/azure-vote-front:v1
# tagging 됐는지 확인
docker images
# acr 주소 사용하여 push
docker push 0503acr.azurecr.io/azure-vote-front:v1
이제 리눅스의 acr에 docker image가 push 되었다.
# 생성한 acr repository에 있는 이미지 리스트로 출력
az acr repository list --name 0503acr --output table
docker images 해서 다시 확인
# 태깅한 버전 목록 확인
az acr repository show-tags --name 0503acr --repository azure-vote-front --output table
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \ #워크 노트
--generate-ssh-keys \
--attach-acr 0503acr
az aks create \
# 위에 코드 아래처럼 필요한대로 수정 후 사용
az aks create \
--resource-group 0503 \
--name 0503aks \
--node-count 2 \
--generate-ssh-keys \
--attach-acr 0503acr \
--location eastus2 # 지역 설정
버츄얼 머신을 미리 두 대정도 세팅을 해주는 것이다(virtual machine scale set)
여기에 우리가 세팅만 잘하면 vm가 부하돼면 추가로 가상머신이 생긴다.
그리고 그 vmss에는 부하 분산기라는 게 껴있어서 사용자가 늘어나면 서버에 적절히 나눠보내줌
또 서버를 하나로 묶기위해 가상 네트워크인 v-net도 필요하게 된다.
밖에서 보면 부하분산기만 보이는 구조. 즉 ip넘버는 하나만 필요한 것(부하분산기의 공용 ip넘버, 부하분산기 =load balancer)
---
azure VMss 쿠버네티스를 붙이게 된다면 쿠버네티스에 워크노드가 부족할 때마다 자동으로 사용가능해진다
그래서 AKS를 만들면 VMss가 같이 생긴다
여기서 새로생긴 공용 ip주소는 부하 분산 장치가 사용하는 것이고 가상 네트워크, 확장집합(vmss)가 생긴 거 볼 수 있다.
쿠버네티스 cli 설치
sudo az aks install-cli
# 잘 설치되었는지 확인할 겸 로그인 인증(리소스 그룹과 aks 이름 수정)
az aks get-credentials --resource-group 0503 --name 0503aks
# Kubernetes 클러스터에 대한 연결 확인(Kubernetes 클러스터는 여러 개의 노드로 구성된 컴퓨팅 환경)
kubectl get nodes
# 출력되는 값은 연결되어있는 가상머신이다
# 리소스 그룹에 있는 acr 리스트 보기
az acr list --resource-group 0503 --query "[].{acrLoginServer:loginServer}" --output table
# 소스 파일 수정해보자(git에서 받은 파일 있는 디렉토리에서 해야 열림)
vi azure-vote-all-in-one-redis.yaml
------------------------------------------------------
이부분의 경로를
containers:
- name: azure-vote-front
image: mcr.microsoft.com/azuredocs/azure-vote-front:v1
이렇게 acr 경로로 수정
containers:
- name: azure-vote-front
image: <acrName>.azurecr.io/azure-vote-front:v1
------------------------------------------------------
:wq 하고 저장닫기
애플리케이션 배포
# 해당파일 기반으로 배포하라
kubectl apply -f azure-vote-all-in-one-redis.yaml
애플리케이션 테스트
# -w 옵션과 같은게 --watch 로 계속 감시하는 옵션
kubectl get service azure-vote-front --watch
# 전체 pod 갯수 확인
kubectl get pods
# 이때 결과에 restart한 얘들은 좀 불안정한 pod
# pod 크기 조정, pod 갯수 늘리기
kubectl scale --replicas=5 deployment/azure-vote-front
# 전체 pod 갯수 확인
kubectl get pods
# 이제 pod가 azure-vote-front에 관한 pod가 5개로 늘었다.
Pod 자동 크기 조정
# AKS 클러스터 버전확인
az aks show --resource-group 0503 --name 0503aks --query kubernetesVersion --output table
# 크기 조정, cpu %가 50을 넘으면 하나씩 pod늘리기, 기본 pod는 3개 유지, 최대 10개까지만
kubectl autoscale deployment azure-vote-front --cpu-percent=50 --min=3 --max=10
# 자동 조정기의 상태를 확인
kubectl get hpa
수동으로 AKS 노드 크기 조정
# 노드의 갯수 변경
az aks scale --resource-group 0503 --name 0503aks --node-count 3
지금까지 한일:
git hub에서 소스코드 다운받아서 이걸 가지고 웹사이트를 운영, 이 내용을 기반으로 도커 이미지를 나왔다. 도커 이미지를 만들때 우린 도커 컴포즈를 이용했다. 그리고 만들어진 이미지를 acr에다가 올렸다. 그리고 acr에 올린 내용을 aks(애저 쿠버네티스 서비스)로 올려서 서비스에 접속했다.
클라우드기 때문에 오토 스케일링이나 노드 증가를 시키는 일을 할 수 있었다.
이 다음 튜토리얼에서 할일:
소스코드에서 변경사항이 발생이 됐을 때, acr과 aks에도 업데이트 해야하는데 이걸 묶어서 업데이트하는 걸 해보자.
이런 과정을 devop라고 부른다.
devops: 프로젝트 계획짜고 설계해서 코딩해서 만들면 패키지나 라이브러리로 build한다. 그후 테스트하고 정식으로 release한다. 그 후 배포(deploy)하고 운영하고 잘돌아가는지 모니터링도 하고 모니터링에서 나오는 피드백 나오면 다시 계획짜고.... 반복...
MLOps: 데이터 프로세싱하고 머신러닝으로 개발하고 운영하고 피드백 받고 다시 데이터 프로세싱...
cd $HOME (그냥 cd home하면 home이란 이름의 디렉토리 찾기 때문에 예약된 $HOME이란 이름 사용)
mkdir 파일 만들기
dir 있는 파일들 보기
ls -al 숨겨지고 자세한 정보보기
touch 빈 텍스트 파일 만들기
cat 텍스트 파일 안에 내용 보기
FROM 퇴적층처럼 쌓아올린 docker file 에서 한층 더 쌓아서 docker를 만들 수도 있는데 그 이전까지는 base image라고 하는데 그런 base image를 어디부터 사용할지 지정
COPY 특정한 파일 혹은 디렉토리를 복사해서 넣어준다
RUN (도커 파일을 가지고 도커 이미지 만들 때 사용한다) 도커 컨테이너가 실제로 동작이 될 때 만약 ubuntu 환경이라면, 안에 환경 세팅도 되어있을 것이다(np, pd, sklearn). 안에 환경 세팅을 넣어주는 것도 방법이지만 RUN 뒤에 명령어로 저런 환경 세팅을 설치해주는 방법도 있다. 또는 text file안에 필요한 걸 다 써주고 그 파일을 실행하라고 명령할 수도 있다.
CMD (도커 이미지를 가지고 도커를 실행할 때) 컨테이너가 실행될 때 딱 하나의 명령만 실행할 수 있다. 주로 파이썬으로 짠 코드가 바로 실행되길 바란다할 때 사용(CMD python main.py)
WORKDIR 작업할 디렉토리 지정, 지정한 명령들이 그 안에서 작동, 생략하면 그냥 home디렉토리에서 실행
ENV 시스템 환경 변수 세팅, kay와 value로 이루어져 있다.
EXPOSE docker를 이용하여 작업할 때, 내가 사용하는 시스템 위에서 그 docker 컨테이너들이 동작할 텐데 바로 외부에 접속이 안된다. 왜냐하면 일단 docker 자체는 외부로 부터 보안상 격리당해있기 때문이다. 그래서 특정 docker는 외부로 통신을 위해 열어줘야하는 작업을 해야한다. 포트와 프로토콜 값이 필요한다 프로토콜 지정안해주면 기본적으로 TCP로 된다.
이번 과정에서는 도커를 직접 만들지만 관리는 어떻게 하는 게 좋을까?
예제로 티켓 링크 웹사이트를 만들고 컨테이너를 하나 만들었을 때, 유명한 가수 콘서트를 하면 사용자들이 폭주할텐데 그럼 도커 컨테이너 하나로는 부족하고 컨테이너를 많이 늘려야할 것이다. 그럼 컨테이너 갯수가 자동으로 늘었다가 사용자가 줄면 다시 자동으로 줄기를 원할 것이다. 이걸 하나하나 손수 하긴 힘들기 때문이다. 이 때 사용하게 되는데 쿠바네티스이다.
docker file만들기
cd $HOME
mkdir docker-practice
cd docker-practice/ 해당 파일로 들어오기 #cd docker 까지 치고 tab누르면 파일이름이 변별력이있어 나머지 자동입력해줌
#이제 여기 텍스트 파일을 하나 만들건데 Dockerfile이미 정해져있는 거니까 대소문자 잘지키기
touch Dockerfile
ls # 위에 만든 Dockerfile 파일 생성된 거 알 수 있다.
cat Dockerfile # 안에 내용없음
docker image 만들기 준비
vi Dockerfile # vi에디터로 열기
#i 눌러서 insert 모드로 변경
#도커 베이스 이미지 지정
FROM ubuntu:18.04
# Apt-get 업데이트 자동으로
RUN apt-get update # Docker 안이라 sudo 하지 않아도 된다
#도커 실행될 때["명령어","명령어 파라메터"]
CMD ["echo","Hello Microsoft AI 2"] # 명령어는 리눅스언어로 사용
#저장
ESC 키로 명령모드로 변경
:wq #저장하고 빠져나가기
#저장 잘 되었는지 확인
cat Dockerfile
docker image 만들기
# build 명령어로 같은 디렉토리내 파일 참조해서 'my-image:v0.0.0' 이란 이미지 만든다
# -t 는 태그(버전)를 달아준다는 뜻
# 끝에 .은 이미지를 이 위치에 만들겠다는 뜻
docker build -t my-image:v1.0.0 .
# 이제 설치가 됐을 것이다.
#도커파일이 있고 이미지는 어디 생겼는지 확인
docker images
지금 사용중인 리눅스 가상 pc가 있고 여기엔 지금 docker를 설치하고 docker image를 생성한 상태.
도커 컨테이너를 만들어서 실행을 해보자.
#생성해둔 이미지로 컨테이너 만들기
docker run --name demo1 my-image:v1.0.0
docker image 활용 방법1
local pc에서 사용
docker image 활용 방법2
내 파일 시스템에만 있던 docker image를 다른 사람과 공유하여 사용하고 싶을 때
(1)서버(local docker rigistry의 역할)를 하나 만들어서 업로드한다. 필요할 때 서버에 요청해서 다운로드 받아 사용
(2) 클라우드 이용. docker hub 라는 사이트를 이용하여 이 곳에 docker image업로드 하여 사용
docker image 활용 방법3
클라우드 이용. Azure의 ACR 서비스 이용하여 도커 파일 바로 올려 사용가능
또 AKS(애저 쿠버네티스 서비스)도 있는 거 참고
저장되는 공간은 repository 저장하는 시스템은 rigistry
docker image 활용 방법1
<Local repository 활용 : 우리가 만든 서버에 docker image 넣기>
# registry 이미지 만들기(registry도 이미지로 가져와야함)
# -d :daemon / -p: 외부에서 접근할 포트넘버(들어오는 포트 :나가는 포트 ) / 컨테이너 이름 registry로 짓기
docker run -d -p 5000:5000 --name registry registry
docker ps # 이제 registry 라는 컨테이너 실행중인게 보인다
# 내가 만든 my-image와 registry 이미지가 있는지 확인
docker images
#image 중에 내가 찾고싶은 이미지 쉽게 찾기
docker images | grep my-image
#이제 resistry에 도커 이미지를 넣어보자
# my-image:v1.0.0는 앞으로 localhost:5000의 my-image:v1.0.0라고 지정
docker tag my-image:v1.0.0 localhost:5000/my-image:v1.0.0
# 이미지 밀어넣기, local host:(포트넘버)에 접속하여 넣는다는 뜻
docker push localhost:5000/my-image:v1.0.0
#공장이나 군대에선 이렇게도 쓰는데 보통은 클라우드 사용
#push 잘되었는지 확인
curl -X GET http://localhost:5000/v2/_catalog
# 더 자세히 알아보자
curl -X GET http://localhost:5000/v2/my-image/tags/list
# 초반 설치할 때 'cli'는 command line interface의 약자로 명령어로 입력하는 모든 도구를 CLI라고 부른다
# docker hub 접속
docker login
#내 docker hub id과 passward 입력해서 로그인
# docker hub, wlsl6569/my-image:v1.0.0에 로컬작업했던 my-image:v1.0.0를 연결
docker tag my-image:v1.0.0 wlsl6569/my-image:v1.0.0
#image push
docker push wlsl6569/my-image:v1.0.0
# cmd에서 아래 명령어 입력해서 다운로드(curl -LO는 웹서버에 있는 것 다운로드)
curl -LO https://storage.googleapis.com/minikube/releases/v1.22.0/minikube-linux-amd64
#확인
ls
# 설치
sudo install minikube-linux-amd64 /usr/local/bin/minikube
#잘 설치됐나 확인
minikube version
minikube --help 설치확인 완료
#이제 워크노드와 쿠베 마스터까지 연결설치 되어있다
# ctl 다운로드
curl -LO https://dl.k8s.io/release/v1.22.1/bin/linux/amd64/kubectl
# ctl 설치, 권한 위치도 같이 줘야함(전체 쿠버네티스를
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# -o root owner가 root라는 뜻 group도 root라는 뜻
# 설치됐는지 확인
kubectl version
kubectl --help
# minikube 실행
minikube start --driver=docker
# 실행되며 cpu2개와 4GB 메모리를 사용하는 걸 볼 수 있다. (최소 사양)
# 현재 상태 확인
minikube status
# pod에 대한 정보 보기(pod는 워크노드에서 컨테이너 담는 그릇)
kubectl get pod
# 이 system에 사용하고 있는 pod 보기
kubectl get pod -n kube-system
# minikube 삭제하기
minikube delete (메모리에 있는 미니쿠베만 삭제하는 거고 미니쿠베 자체를 삭제하려면 minikube uninstall)
인간이 쉽게 읽을 수 있고 쓸 수 있는 데이터 직렬화 양식입니다. 주로 데이터 구조, 설정 파일 및 메시지 전송 프로토콜 등에서 사용,( YAML말고 JSON포맷도 많이 사용)
데이터의 직렬화?
예를 들어 어떤 Class를 만들었다하면, 그 안에 method와 property가 있고 여기 속성도 여러개 있을 것이다.
이 class를 A 시스템에서 잘 사용하다가 B 시스템으로 보낸다고 할 때 네트워크로 보내고 싶을 때 "api의 버전
보내려는 종류(kind)
추가적인 정보 (meta data: sample)
클래스의 스펙 (method : Run, view, save)프로퍼티 (name, color....ect)"이런 정보를 다 텍스트로 풀어써서 네크워크로 보내는 것이다. 그러면 시스템 B에서도 그 상세스펙을 보고 class를 잘 복원할 수 있다. 이게 바로 직렬화이다.
YAML 포맷 특징?
-가독성 : 사람이 읽기 쉽도록 디자인, 해당되는 객체의 설계 도면을 적어둔 느낌
문법 구조?
- Key-Value 조합
- #을 사용하여 주석 처리
자료형?
-string (문자) : "로 감싸주는 게 좋다, 특히 숫자를 문자열로 써야할 때, YAML예약어와 겹칠때(y,yes,true..), 특수문자
-integer(정수): 일반 숫자나 16진수 표현 방식
-float(소수)
-exponential type(지수형)
-list : [ ]이나 한줄씩 나열 가능
예시)
container:
-name : busybox
image: busybox:1.25
-Multi-line strings : \n처리하여 새로운 줄로 내려가게 하기
-구분선 : 하나의 yaml파일에 여러개의 도큐먼트 작성(---)
YAML파일은 vi에디터로 만들어보자
yaml 포맷으로 POD 파일 생성
# 파일생성
vi pod.yaml
# i 눌러서 인서트 모드
apiVersion: v1
kind: Pod
metadata:
name: counter #metadata 하위항목 들여쓰기
spec:
containers:
- name: count
image busybox # docker image
args: [/bin/sh, -c, 'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
# 1초 마다 시간 업데이트하는 거 busy box로 만듦
#esc키 눌러 명령 모드로 바꾼후 저장 나가기
:wq
# 내용 확인
cat pod.yaml
# file옵션으로(pod.yaml에 써있는대로) 적용해줘
kubectl apply -f pod.yaml
# 하드 생성완료
#하드가 생성되고 실행이 잘되고 있는지 확인
kubectl get pod
# 이때 minikubes 실행된 상태여야한다
# system과 관련된 pod 확인
kubectl get pod -n kube-system
#전체 포드 확인
kubectl get pod -A
# 지정된 포드만 보기
kubectl get pod counter
#각각의 pod에 대한 자세한 정보, 과정까지 다 나옴
kubectl describe pod counter
# 각각의 하드에 대한 정보 볼 수 있는 또 다른 방법, describe보단 더 깔끔하고 ip number를 보여준다.
kubectl get pod -o wide
# 지속적으로 각각의 pod의 상태를 감시
kubectl get pod -w
ctrl + c 로 종료
#kubectl 사용하여 만든 busybox 로그확인(counter 하드이름도 입력)
kubectl logs counter
pod 자체에 접속하기, 삭제하기
# 직접 pod에 it 모드로 접속, 포드이름(counter), /접속할 쉘
kubectl exec -it counter /bin/sh
# pod 삭제하는 법(1) pod 이름으로 삭제
kubectl delete pod counter
# pod 삭제하는 법(2) 지정된 파일에서 설명하고 있는 pod 삭제
kubectl delete -f pod.yaml
# 잘 삭제되었는지 확인
kubectl get pod
# 파일 생성
vi deployment.yaml
# i눌러서 인서트 모드로 변경 후 작성
apiVersion: apps/v1
kind: Deployment #배포단위
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # pod 인스턴스 갯수
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers: # 컨테이너 정보
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 배포
kubectl apply -f deployment.yaml
# 돌아가고 있는 pod 확인
kubectl get pod # 3개의 pod(replica)가 돌아가고 있다
# deployment 조회
kubectl get deployment
# 이때 3개의 pod에서 20개의 pod로 늘려야할 때 scale 조절
kubectl scale deployment/nginx-deployment --replicas=20
# 확인작업
kubectl get deployment
kubectl get pod
------------------------------------------
삭제작업
# pod가 죽거나 응답이 없으면 관리하는 쿠버네티스 마스터에서 얘를 죽이고 새 pod만든다(auto-healing 기능)
# pod를 강제로 죽이고 다시 생성되는지 확인해보자
#pod 목록보고 죽일 pod 이름 복사해둘것
kubectl get pod
# 삭제
kubectl delete pod '복사한pod이름'
#pod 목록에 다시 생성됐나 확인
kubectl get pod
# deployment 삭제
kubectl delecte deployment nginx-deployment
# 삭제된 deployment에 속해있던 pod들 같이 삭제된 것 볼 수 있다
kubectl get pod
다시 한번 쿠버네티스 구조를 떠올려보면 워크 노드에는 포트가 있고 컨테이너가 그 안에 들어있다. 각각의 pod마다 ip address가 할당이 되어있는데 이 ip address를 직접적으로 연결해 사용하기에는 pod가 다시 죽었다가 살아날 수 있어 비효율적이다. 그걸 피하기 위해 포드에 가상화된 리소스, 서비스라는 개념을 새로 만든다.
외부에서 연결할 때는 서비스까지만 연결하면 된다.
현재 실습에서는 가상머신을 사용하고 있고 network security group이라는 방화벽이 가상머신에 붙어있기 때문에...방화벽을 먼저 풀어줘야한다는 한계점이 있다
IP address는 총 32bit 숫자로 구성, (2^8 = 255, 즉 범위가 0~255까지가 4번)
이걸 IPv4방식이라고 한다.
즉 사용한 IP가 한정되어 있어 기기 수 만큼 충분하지 않아 다른 방법이 나온다.
(1) 8+8+8+8+8+8 로 주소체계를 2자리 늘리기 - 48bit 체계, IPv6방식,
또한 아래 이유로 IP address가 충분해졌다.
(2) DHCP : ip address를 부여했다가 빼앗는 방식(많은 인원이 컴퓨터 사용하는 그룹에서 사용)
회사같은 곳에서는 IP address를 인원의 80%정도만 부여하고 사람들이 컴퓨터를 켜면 그때 ip address를 부여해줬다가 회수
(3) private network :
cmd창에 ipconfig 쳐보면 나의 ip 주소 체계를 볼 수 있다. 여기서 IPv4로 접근할 수 있다고 생각할 수 도있지만 안된다. 왜냐하면 프라이빗 네트워크(사설망) 기기마다 ip주소를 부여하기엔 부족해서 gateway(집에선 보통 인터넷공유기가 그 역할)가 공용 IP address(외부에서 접속가능한 퍼블릭 어드레스)는 따로 있고 private network(내부적으로 사용되는 네트워크)는 또 따로 있어서, 게이트 웨이를 거쳐서 퍼블릭 어드레스로 바꿔주고 다시 연결 받아야할땐 내부 어드레스 중 몇번이었는지 게이트웨이가 확인하고 보내줌.
그래서 사설망으로 direct로 요청하면 안되고 게이트웨이에 요청해야함
Docker는 퍼블릭 ip를 부여받고 안에 컨테이너는 privat IP를 할당받아 도커 안에서만 사용하게 되있는데, 그래서 이 사설네트워크는 퍼블릭IP로, 퍼블릭 IP는 사설 네트워크로 바꿔주는 명령이 필요하다.
서비스 만들기
vi service.yaml
----------------------------------------------------------
apiVersion: app/v1
kind: Service
metadata:
name: my-ngnix
labels:
run: my-nginx
spec:
type: NodePort # 노트포트는 도커를 열어서 외부에서 접속 가능하게 해주는 것
ports:
-port: 80
protocol: TCP
selector:
app: nginx
----------------------------------------------------------
kubectl apply -f service.yaml
kubectl get service # port 80:<port> 숫자확인
curl -X GET $(minikube ip):<PORT> # 외부에서도 POD에 접속가능 확인
-유투브 따배쿠 쿠바네티스 강좌 추천 -
정리
-docker 파일 만들어 docker image만들 수 있고 이런 것들은 컨테이너로 만들어 local pc나 docker hub 등에서 push하여 공유할 수 있다.
-그리고 컨테이너를 관리하는 쿠버네티스 에서는 컨테이너를 pod라는 개념안에 보관한다. pod가 응답이 없거나 죽으면 쿠버네티스 마스터가 죽이고 새로 생성을 한다. pod는 yaml 양식의 파일로 직접만들거나 deployment 로 여러개를 인스턴스로 만들 수 있다.
cmd로 명령 프롬프트 열기. ssh만 치고 입력했을 때 '알수없는 명령입니다' 이런거 안뜨면 ssh 쓸 수 있다는 것이다.
이제 애저 포탈 우분트 가상머신으로 와서 연결 누르고 SSH 누르고 4번 항목에 아이디 @ IP주소 부분 복사해서 cmd에서 ssh + 복붙하고 로그인하기
ssh? 우리가 접속하는데 사용한 ssh는 secure shell의 줄임말로 통신을 할 때 암호를 걸어서 보내고 받을 때 암호를 풀어서 받는 방식(프로토콜)이다.
이 과정까지는 도커를 사용하기 위해 이제 리눅스 환경을 만든 것이다.
이제 우분투나 리눅스 환경에 들어오면 습관적으로 apt-get undate (리눅스 최신 버전 설치)해줘라. permission denied가 뜨면 권한을 얻기 위해 sudo apt-get update 명령을 줘라.(이때 권한이 처음에 없는 이유는 보안때문이다. $ 상태가 붙으면 권한없는 평민 상태라는 거고 #이면 내가 최고권한자라는 이야기. 내가 권한없는 평민일때 가끔 권한이 필요하면 sudo라는 명령을 쓰는 것이다. sudo는 'super user do' 의 약자이다)
sudo apt-get upgrade도 해줘라
그 후 docker 입력해보면 docker는 없지만 설치할 수 있다고 뜬다 . 그렇지만 이렇게 설치안할 거임.
(2) 이제 컨테이너를 사용을 할 때 pc에서 개발이 끝나면 실제 서버에 보내야하는데 바로 다이렉트로 컨테이너를 보내면 안되고 준비가 필요하다. 그 중간과정이 필요하고 '컨테이너 repository'라고 부른다. 컨테이너를 레포지토리에 다시 저장하고 서버는 레포지토라에서 다운로드하여 사용하는 것이다. 레포지토리는 내 컴퓨터에도 만들 수도 있고 클라우드나 별도의 서비스를 이용해서 만들 수도 있다. 마이크로소프트 애저 안에도 이런 서비스가 있다(ACR = AzureConrainerRepository)또 깃허브와 비슷한 기능을하는 DockerHub를 이용할 수도 있다.
도커가 어느 레포지토리를 바라보는지 알아야함 아래 echo로 시작하는 명령이 레포지토리를 지정하는 건데 보면 docker hub에 연결되어 있음( ~>/dev/null)
이제 다음 명령어를 쳐봐라 docker run hello-world 권한 거부가 될 것이다. 근데 매번 sudo를 할 수는 없으니 sudo를 빼고 실행할 수 있도록 해보자.
유저모드 바꾸기로 일반 유저들에게도 권한을 주겠다는 명령 : sudo usermod -a -G docker $USER
재실행해야 모드변경 적용되기 때문에 sudo service docker restart 해서 시스템 다시 재시작하고 exit 해서 재로그인도 해준다(애저에서 아이디 ip복붙)
sudo usermod -a -G docker $USER
sudo service docker restart
exit
이제 docker run hello-world도 실행이 될 것이다 (이 명령 실행된 것을 보면 pull로 어디서 파일을 가져오고 hello-world라는 image 가져온 것을 알 수 있다. 즉 이 명령은 docker run-도커를 실행시켜라 hello-world라는 것을. 근데 실행된 걸 보면 우리 pc에는 hello-world라는 이미지가 없다, 그래서 레포지토리(도커 허브)에서 가져온 것이다.이제 이걸 가지고 컨테이너를 실행시킬 수 있다. )
필요한 이미지만 내쪽으로 땡겨오기 docker pull --help 도커 명령어등 보기 docker --version 도커 버전보기
docker pull ubuntu:18.04 필요한 이미지(ubuntu)태그, 즉 버전(18.04)과 함께 작성(Digest 이미지의 고유번호) 이제 내 리눅스에 우분트 18.04 버전이 설치된 것이다.
이제 컨테이너가 있으면 컨테이너를 만들 수 있는 파일 형태를 이미지라고 부른다. 그럼 이제 현재 로컬에 몇개 이미지가 있는지 확인해보자.
로컬에 어떤 이미지 있는지 확인 docker images 여기 용량이 작은 이유는 통용되고 있는 기술을 제외한 이 버전의 이미지(우분투18.04)에만 있는 특성만 저장하기 때문이다.
이건 리눅스 프로세스 명령, 뭐가 돌아가고 있는지 확인, ps 이 명령어 결과 중 PID는 각각의 프로세스에 부여된 고유한 번호이고, 만약 이상한 프로세스가 있으면 고유 번호로 죽일 수 있다. TTY는 터미널을 의미하는데 터미널 몇번에서 작업하는지 알려주고 있다(예전엔 컴퓨터 하나에 여러개 컴퓨터 연결하여 터미널 여러개로 사용했기 때문).
어떤 도커 돌아가는지 보자 docker ps
모든 정보 보기 docker ps -a
가지고 있는 이미지 실행, 이름도 지어준다docker run --name demo1 -it ubuntu:18.04 /bin/bash
이제 경로가 바뀌었을 것이다 -it는 인터렉티브 터미널이란 뜻의 명령으로 해당되는 도커에 들어가서 명령어를 칠수 있게 해준다. ubuntu18.04 를 실행하고 / bin/bash ..bin은 실행파일이 모인 파일이고 여기있는 bash 쉘 프로그램을 실행한다는 뜻도 붙여주었다.
이제 $가 아닌 #이 붙음으로써 최고권한자로 이 우분투18.04버전 컨테이너 안에 들어온 것을 알 수 있다.
apt-get update apt-get upgrade
해주기
필요하면 컨테이너를 여러개 실행시킬 수도 있다.또 만약 여기서 빠져나가고 싶으면
exit로 나가서 host os (애저에서 선택한 우분투20.14??)버전으로 돌아감
윈도우즈 cmd에서 'dir'이나 'cd 경로' 명령 등을 입력하면 처리해주는 건 명령어 안에 cmd라는 애가 빡세게 일해주고 있기 때문이다.(cmd.exe 예전엔 command.com였음)
이런 명령어 처리기가 운영체제마다 모두 있다. 리눅스나 유닉스 경우에는 born 혹은 bash 같은 것들이 그 역할을 한다. born shell같은 경우에는 요즘 거의 안쓰고 bash shell을 쓴다.
exit 해서 host os로 나가기 docker ps 해서 컨테이너 실행중인거 있는지 확인-도커는 끊으면 종료가 돼서 아마 아무것도 없을 것이다. 근데 만약 웹서비스를 만들어 배포하면 계속 돌아야하는건 어떻게 만들까?
docker run -it -d --name demo2 ubuntu:18.04
-d는 daemon의 약자 : 도커가 계속 메모리 상에 계속 끊기지 않고 돌아야할 때, 어떤 서비스등을 만들 때 사용
이제 docker ps 하면 계속 돌아가는 거 알 수 있다. 도커에 접속을 해보자 , 명령 처리할 쉘도 정해주기
이제 demo2 컨테이너에 들어간 것이다 다시 exit로 나가도 docker를 daemon으로 실행시켜서 죽지 않는다.
docker ps -a 실행시켜서 도커들 히스토리부터 현재까지 보면 up 상태인거 있을 텐데 (demo2) 메모리 상에 올려져 있다는 뜻이다.
앱에서 웹서버에 요청을 하는 구조 만들 때 예시
어떤 서비스를 만들려고 한다면 일단 웹서버가 필요할 것이다. ubuntu20.04 버전을 사용한다고 가정하고 여기 웹서버를 설치한다 그후 데이터베이스는 ubuntu22,04이고 데이터베이스는 mySQL을 설치했다고 해보자. 그러면 도커 컨테이너에 이미지를 만들어넣는다. 그럼 웹서버 이미지를 가지고 런해서 웹서버를 하나 만들것이다(web01) 그럼 이제 데이터 베이스도 우분투 위에 mySQL 가지고 db01 이미지를 따로 만들고 할 것이다. 이런식으로 시스템을 구축하다 보니 이 서비스에 사용자가 늘어 컨테이너 용량이 부족할 수도 있다. 그러면 이제 컨테이너를 늘려주는 것이다. web02~web10 이러면 웹 트래픽을 분산처리할 수 있게 된다.
이렇게 도커를 관리하는 일이 필요해지며 쿠버네티스가 나오게 되었다. 쿠버네티스 자체가 작은 클라우드라고 할 수 있다.
도커에 로그 확인 docker logs demo1 모든 기록을 보여준다.
busybox라는 이미지 파일 다운로드, 조건이 true인 이유는 내가 탈출할 코드를 안넣으면 무한 반복, echo를 통해 계속 시간을 찍어주라는 간단한 스크립트. 그래서 sleep 1은 1초동안 쉰다.
docker run --name demo3 -d busybox sh -c "while true;do $(echo date);sleep 1;done"
docker logs demo3 해보면 1초에 각각의 일 볼 수 있다.
docker logs demo3 -f -f는 follow 모드로 1초에 한번씩 이 도커가 뭐하는지 알려준다-시스템 모니터링, 끝내야할 때는 crtl + c (^C)
docker ps로 도커 몇개 돌아가나 보기 (위에 과정을 겪었으면 daemon모드로 실행한 demo2, demo3이 살아있다)
그동안엔 우분투18.04버전(이미지)으로 demo(이미지가 메모리 상에 올라와 컨테이너가 되었다)를 만들어 up(실행했다가) 자금 stop으로 메모리 상에 정지시켜둔 것이다.
컨테이너를 아예 지우려면 어떻게 할까?
docker rm demo3 (메모리상 컨테이너만 삭제) 그 후 docker ps -a로 지워졌는지 확인
컨테이너 이름이 없을 때는? docker ps -a 옵션에 임의로 지어진 이름이 있으니 이걸 보고 지워라
또 안쓰는 이미지들도 용량을 차지하니 삭제할 필요가있다 지금 있는 이미지 확인하기
docker images
이미지를 삭제라는건
docker rmi hello-world(이미지 이름) => 에러가 난다면 컨테이너로 사용되는 게 있는 이미지는 삭제가 안되기 때문에 먼저 컨테이너 모두 삭제해줘야한다.
태그(버전) 있는 건 정확히 입력해 삭제할 것, 아니면 무조건 최신 것을 삭제함 docker rmi ubuntu:18.04
docker rmi busybox
docker를 사용할 때 docker file이 쌓여 커지면 감당이 안될 수도 있다. 그래서 도커는 도커 우분투 이미지파일이 하나 있고 이걸로 우분투 20.04 컨테이너를 만들려고 한다면 메모리에 절반정도는 우분투 20.04버전으로 채우고 남은 반의 반은 web01:0.1 버전으로 만들고 그 위에 또 web01:0.2 버전을 또 만들 수 있고.. 형태를 레포지토리에 퇴적층처럼 차곡차곡 쌓이게 했다 그래서 쌓인 부분 중에서 필요한 부분만 다운로드하게 해서 훨씬 더 가볍게 되어있다.
그래서 이미지 삭제를 할 때 보면 두개가 삭제된 기록을 볼 수 있는데 이건 즉 여러 퇴적층을 다 삭제해서 그렇다.
이제 도커 파일도 만들 수 있어야하고 도커 이미지도 만들어야함..
<도커 이미지 만들기>
이를 위해선 vi 명령어를 알아야 한다. vi는 일종의 에디터로 텍스트 편집기다
vi test.txt 이 파일에서 vi 에디터 시작하기
insert(편집) 모드로 바꾸기 = i 이제 내용을 입력할 수 있음, 그러나 편집모드는 글만 다루는 곳으로 저장할 수 없다.
파일을 저장하려면 저장명령을 내려야 한다.-> command mode로 나와야함
command mode로 바꾸기 = esc
저장을 위해서는 아래쪽에 :w (써라)명령 쓰기, 엔터. 그럼 저장이 된 것이다. :q 는 vi 모드를 탈출