Windows 운영체제에서는 PowerShell이나 Windows Subsystem for Linux(WLS)을 사용하여 Linux에서 사용되는 Bash 셸과 같은 셸을 사용할 수도 있다. 나는 window 스토리지에서 windows powershell을 받아 사용 중.
셸의 역할
-사용자 명령어 해석기 : 내가 명령어를 쓰면 셸이 해석에서 운영체제 커널에 전달해줌
-사용자가 프롬프트에 입력한 명령을 해석해서 운영체제에 전달
셸의 종류
1. Bourne shell(sh) : 벨 연구소에서 만든 최초의 셸
2.C shell(csh) : c언어 문법 적용
3. Korn shell(ksh) : 첫번째 본셸에 c셸을 적용
4. Bourn-again shell(bash) : csh과 ksh이 가진 기능 포함하며 sh과 호환도 높여 많이 사용
기본 셸 구성하기
현재 시스템에서 사용가능한 셸 리스트 확인 : $ cat /ect/shells
현재 내가 쓰는 셸 확인 :$ echo $SHELL
사용하는 셸 변경 : sudo chsh [username] (변경된 내용은 passwd파일에 저장된다)
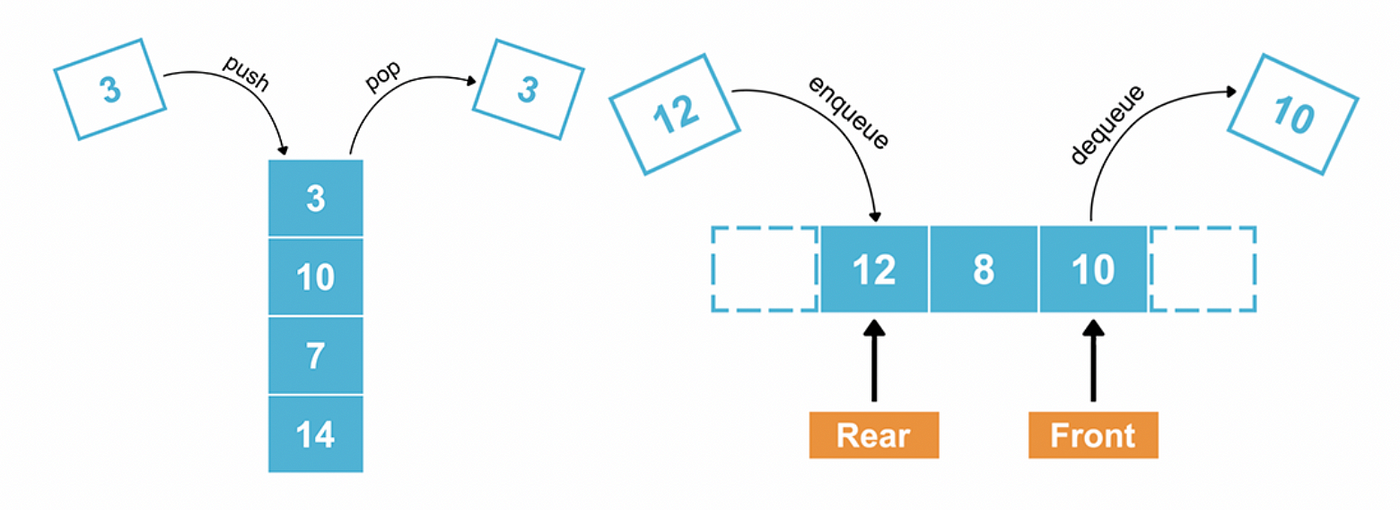
스택(Stack)과 큐(Queue)는 컴퓨터 과학에서 가장 기본적인 자료 구조 중 하나입니다.
스택은 LIFO(Last-In-First-Out) 원칙에 따라 데이터를 저장하는 자료 구조입니다. 새로운 데이터는 스택의 가장 상단에 추가되며, 데이터를 꺼낼 때에는 가장 상단에 있는 데이터부터 차례대로 꺼내야 합니다.
큐는 FIFO(First-In-First-Out) 원칙에 따라 데이터를 저장하는 자료 구조입니다. 새로운 데이터는 큐의 가장 뒤에 추가되며, 데이터를 꺼낼 때에는 가장 앞쪽에 있는 데이터부터 차례대로 꺼내야 합니다. 이러한 특성 때문에, 큐는 주로 작업 대기열(job queue) 등에 활용됩니다.
스택과 큐는 각각의 특성 때문에 다양한 알고리즘과 데이터 구조에서 중요한 역할을 합니다. 스택과 큐는 둘 다 리스트와 같은 데이터 구조를 기반으로 하며, 파이썬에서는 리스트를 이용하여 스택과 큐를 구현할 수 있습니다.
from sklearn.svm import SVR # classfication에 쓰는건 SVC, regression에 쓰는건 SVR
svm_regre = SVR()
svm_regre.fit(X_train['s6'].values.reshape((-1,1)),y_train)
y_pred = svm_regre.predict(X_test['s6'].values.reshape(-1,1))
print('단순 서포트 벡터 머신 회귀, R2: {:.2f}'.format(r2_score(y_test, y_pred)))
출력>
단순 서포트 벡터 머신 회귀, R2: 0.06
for i in [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]:
svm_regr = SVR(C = i) # 기본값 c = 1 , 높아질수록 데이터에 집착하지 않고 노멀하게 예측하게된다(전체 트랜트 예측)
svm_regr.fit(X_train, y_train)
y_pred = svm_regr.predict(X_test)
print('다중 서포트 벡터 머신 회귀,i={} R2: {:.2f}'.format(i, r2_score(y_test, y_pred)))
출력>
다중 서포트 벡터 머신 회귀,i=1 R2: 0.17
다중 서포트 벡터 머신 회귀,i=2 R2: 0.29
다중 서포트 벡터 머신 회귀,i=3 R2: 0.35
다중 서포트 벡터 머신 회귀,i=4 R2: 0.39
다중 서포트 벡터 머신 회귀,i=5 R2: 0.42
다중 서포트 벡터 머신 회귀,i=6 R2: 0.44
다중 서포트 벡터 머신 회귀,i=7 R2: 0.46
다중 서포트 벡터 머신 회귀,i=8 R2: 0.47
다중 서포트 벡터 머신 회귀,i=9 R2: 0.48
다중 서포트 벡터 머신 회귀,i=10 R2: 0.49
다중 서포트 벡터 머신 회귀,i=11 R2: 0.49
다중 서포트 벡터 머신 회귀,i=12 R2: 0.50
다중 서포트 벡터 머신 회귀,i=13 R2: 0.50
다중 서포트 벡터 머신 회귀,i=14 R2: 0.50
다중 서포트 벡터 머신 회귀,i=15 R2: 0.50
다중 서포트 벡터 머신 회귀,i=16 R2: 0.50
다중 서포트 벡터 머신 회귀,i=17 R2: 0.50
다중 서포트 벡터 머신 회귀,i=18 R2: 0.50
다중 서포트 벡터 머신 회귀,i=19 R2: 0.50
다중 서포트 벡터 머신 회귀,i=20 R2: 0.50
y_pred = sim_lr.predict(X_test['s6'].values.reshape((-1,1)))
from sklearn.metrics import r2_score
print('단순 선형 회귀, R2: {:.2f}'.format(r2_score(y_test, y_pred)))
print('단순 선형 회귀 계수(w) : {:.2f}, 절편(b): {:.2f}'.format(sim_lr.coef_[0],sim_lr.intercept_))
출력>
단순 선형 회귀, R2: 0.16
단순 선형 회귀 계수(w) : 586.70, 절편(b): 152.60
시각화
#Linear line의 생성
line_x = np.linspace(np.min(X_test['s6']), max(X_test['s6']), 10)
line_y = sim_lr.predict(line_x.reshape(-1,1))
print(line_x)
print(line_y)
#Test data를 표현
plt.scatter(X_test['s6'], y_test, s=10, c='black')
plt.plot(line_x, line_y, c='red')
plt.legend(['Test data sample','Regression line'])